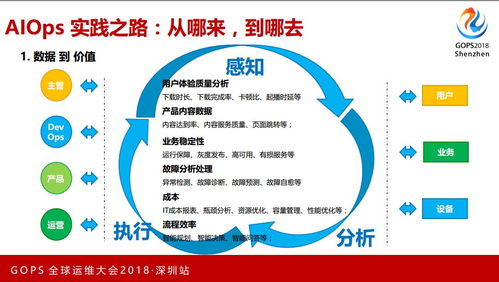
在數(shù)字化浪潮席卷全球的今天,大型互聯(lián)網(wǎng)企業(yè)與組織正面臨著前所未有的運(yùn)維挑戰(zhàn):服務(wù)于億級(jí)用戶,管理著百TB甚至PB級(jí)別的海量數(shù)據(jù),傳統(tǒng)的運(yùn)維模式已捉襟見肘。AIOps(智能運(yùn)維)應(yīng)運(yùn)而生,成為破局的關(guān)鍵。本文將聚焦于AIOps技術(shù)棧中至關(guān)重要的一環(huán)——數(shù)據(jù)處理服務(wù),探討其在應(yīng)對(duì)超大規(guī)模場(chǎng)景下的增強(qiáng)實(shí)踐之路。
一、 基石:面對(duì)百TB數(shù)據(jù)的核心挑戰(zhàn)
構(gòu)建服務(wù)于億級(jí)用戶場(chǎng)景的AIOps平臺(tái),數(shù)據(jù)處理服務(wù)首先需要直面三大核心挑戰(zhàn):
- 數(shù)據(jù)規(guī)模與吞吐:每日產(chǎn)生的運(yùn)維日志、指標(biāo)、追蹤數(shù)據(jù)輕松達(dá)到百TB級(jí)別,數(shù)據(jù)接入、實(shí)時(shí)處理與批量計(jì)算的吞吐量要求極高。
- 數(shù)據(jù)多樣性:數(shù)據(jù)來(lái)源異構(gòu),包括結(jié)構(gòu)化指標(biāo)、非結(jié)構(gòu)化日志、半結(jié)構(gòu)化的調(diào)用鏈數(shù)據(jù),格式繁雜,統(tǒng)一處理難度大。
- 時(shí)效性與準(zhǔn)確性:故障預(yù)警要求近實(shí)時(shí)(秒級(jí)/分鐘級(jí))檢測(cè),而根因分析、容量預(yù)測(cè)等場(chǎng)景又需要處理高維、復(fù)雜的歷史數(shù)據(jù),對(duì)處理的延遲與結(jié)果的準(zhǔn)確性有雙重嚴(yán)苛要求。
二、 增強(qiáng):數(shù)據(jù)處理服務(wù)的架構(gòu)演進(jìn)
為應(yīng)對(duì)上述挑戰(zhàn),數(shù)據(jù)處理服務(wù)需從傳統(tǒng)的“管道”向智能、彈性、融合的“數(shù)據(jù)中樞”演進(jìn)。
1. 分層彈性架構(gòu):
- 接入層增強(qiáng):采用分布式、可水平擴(kuò)展的接入網(wǎng)關(guān)(如基于Apache Flume, Kafka Connect的定制化Agent),支持多協(xié)議、多數(shù)據(jù)源,并具備邊緣預(yù)處理能力(如格式規(guī)整、臟數(shù)據(jù)過(guò)濾),減輕核心鏈路壓力。
- 實(shí)時(shí)處理層增強(qiáng):核心是引入流批一體處理引擎(如Apache Flink)。它不僅能以極低延遲處理實(shí)時(shí)數(shù)據(jù)流進(jìn)行異常檢測(cè),還能無(wú)縫銜接歷史數(shù)據(jù),進(jìn)行時(shí)間窗口內(nèi)的復(fù)雜事件處理(CEP)和狀態(tài)計(jì)算,為實(shí)時(shí)決策提供支持。
- 批量計(jì)算與存儲(chǔ)層增強(qiáng):構(gòu)建基于對(duì)象存儲(chǔ)(如S3/OSS)和分布式數(shù)據(jù)湖(如Hudi, Iceberg)的廉價(jià)存儲(chǔ)底座,配合Spark、Presto等計(jì)算引擎,處理海量歷史數(shù)據(jù)的挖掘、模型訓(xùn)練與離線分析。實(shí)時(shí)與批處理的結(jié)果可統(tǒng)一寫入數(shù)據(jù)湖,形成閉環(huán)。
2. 智能數(shù)據(jù)治理:
- 自動(dòng)化數(shù)據(jù)建模:利用元數(shù)據(jù)管理,自動(dòng)識(shí)別數(shù)據(jù)源、推斷數(shù)據(jù)結(jié)構(gòu),并構(gòu)建統(tǒng)一的運(yùn)維數(shù)據(jù)模型(如將指標(biāo)、日志、事件關(guān)聯(lián)到統(tǒng)一的“服務(wù)-實(shí)例”維度下),為上層分析提供一致視角。
- 數(shù)據(jù)質(zhì)量監(jiān)控:在數(shù)據(jù)處理流水線中嵌入數(shù)據(jù)質(zhì)量檢查點(diǎn),自動(dòng)監(jiān)測(cè)數(shù)據(jù)的完整性、及時(shí)性、一致性,并聯(lián)動(dòng)告警,確保輸入AI模型的數(shù)據(jù)可靠。
- 生命周期智能管理:基于數(shù)據(jù)熱度、訪問(wèn)模式及合規(guī)要求,制定策略自動(dòng)執(zhí)行數(shù)據(jù)的分層存儲(chǔ)(熱、溫、冷)、壓縮與歸檔,顯著降低成本。
3. 算法與處理的深度融合:
- 處理流程嵌入模型:將輕量級(jí)AI模型(如流式異常檢測(cè)算法、日志模式提取模型)直接嵌入數(shù)據(jù)管道。例如,在日志流經(jīng)Kafka時(shí)即通過(guò)實(shí)時(shí)模型進(jìn)行異常模式匹配和關(guān)鍵信息抽取,將結(jié)構(gòu)化結(jié)果同步至下游,極大提升分析效率。
- 特征工程平臺(tái)化:構(gòu)建特征計(jì)算平臺(tái),將常用的運(yùn)維特征(如時(shí)序指標(biāo)的趨勢(shì)、周期性、方差)計(jì)算封裝為標(biāo)準(zhǔn)算子,供數(shù)據(jù)科學(xué)家和工程師在流批任務(wù)中直接調(diào)用,加速AI應(yīng)用落地。
三、 實(shí)踐:關(guān)鍵場(chǎng)景的技術(shù)落地
- 海量日志實(shí)時(shí)解析與索引:結(jié)合流處理引擎與自然語(yǔ)言處理(NLP)模型,對(duì)非結(jié)構(gòu)化日志進(jìn)行實(shí)時(shí)聚類、模式學(xué)習(xí)和關(guān)鍵信息提取,生成結(jié)構(gòu)化事件,并索引到高性能存儲(chǔ)(如Elasticsearch),使百TB日志的查詢與關(guān)聯(lián)分析從“不可能”變?yōu)椤懊爰?jí)響應(yīng)”。
- 多維指標(biāo)異常檢測(cè):面對(duì)數(shù)十億維度的監(jiān)控指標(biāo),利用流處理框架實(shí)時(shí)計(jì)算指標(biāo)的統(tǒng)計(jì)特征,并集成多種輕量級(jí)無(wú)監(jiān)督算法(如S-H-ESD, 移動(dòng)平均)進(jìn)行并行檢測(cè)。將實(shí)時(shí)流與歷史基線(存儲(chǔ)在數(shù)據(jù)湖中)快速對(duì)比,實(shí)現(xiàn)精準(zhǔn)、可解釋的異常點(diǎn)定位。
- 大規(guī)模追蹤數(shù)據(jù)關(guān)聯(lián)分析:處理分布式調(diào)用鏈產(chǎn)生的海量Span數(shù)據(jù),通過(guò)增強(qiáng)的流處理服務(wù),實(shí)時(shí)構(gòu)建完整的調(diào)用樹,計(jì)算服務(wù)依賴拓?fù)洌㈥P(guān)聯(lián)對(duì)應(yīng)的性能指標(biāo)和錯(cuò)誤日志,快速定位跨服務(wù)、跨數(shù)據(jù)中心的性能瓶頸與故障根源。
四、 未來(lái)展望
億級(jí)用戶百TB數(shù)據(jù)場(chǎng)景下的AIOps數(shù)據(jù)處理服務(wù),其增強(qiáng)之路遠(yuǎn)未停止。未來(lái)將向著更自動(dòng)化(如基于強(qiáng)化學(xué)習(xí)的流水線自調(diào)優(yōu))、更云原生(深度整合K8s,實(shí)現(xiàn)計(jì)算資源的細(xì)粒度彈性調(diào)度)、更智能化(處理過(guò)程內(nèi)置更多可解釋AI模型)的方向持續(xù)演進(jìn)。數(shù)據(jù)處理服務(wù)不再僅僅是后臺(tái)支撐,而是驅(qū)動(dòng)AIOps智能進(jìn)化的核心引擎,為系統(tǒng)的穩(wěn)定性、用戶體驗(yàn)與業(yè)務(wù)增長(zhǎng)提供堅(jiān)實(shí)的數(shù)據(jù)動(dòng)能。